
开云体育(中国)官方网站DeepSeek 团队取得了翻新性的改良-开云官网kaiyun皇马赞助商 (中国)官方网站 登录入口
发布日期:2026-03-31 17:28 点击次数:110
来源: DeepTech深科技
当地时候 1 月 30 日,好意思国 AI 公司 Anthropic 的 CEO 达里奥·阿莫迪(Dario Amodei)在个东说念主博客发表“万字檄文”,指出对于 DeepSeek 的崛起,好意思国白宫应该加强顾问。
 (来源:https://darioamodei.com/on-deepseek-and-export-controls)
(来源:https://darioamodei.com/on-deepseek-and-export-controls)

达里奥·阿莫迪博文中枢不雅点:不应将工夫上风拱手让给中国
达里奥·阿莫迪(Dario Amodei)写说念:“我暂且不征询 DeepSeek 是否对 Anthropic 等好意思国 AI 企业组成胁迫,尽管我合计很多对于 DeepSeek 胁迫好意思国 AI 指点地位的说法被严重夸大了。我更柔软的是,DeepSeek 的效果发布是否收缩了好意思国芯片出口顾问策略的合感性。我的意见是抵赖的。事实上,我合计 DeepSeek 的进展反而令出口顾问策略显得比一周前愈加伏击。出口顾问就业于一个至关伏击的目的:确保民主国度在 AI 发展中保抓最初地位。需要明确的是,出口顾问并不是藏匿好意思中竞争的技能。若是好意思国和其他民主国度的 AI 公司思要最终胜出,就必须竖立出比中国更超卓的模子。但是,在力所能及的情况下,咱们不应将工夫上风拱手让给中国。”
此外,达里奥·阿莫迪(Dario Amodei)还怀疑 DeepSeek 使用了禁运芯片。他写说念:“DeepSeek AI 芯片舰队的很大一部分似乎是由以下芯片组成:尚未被退却的芯片(但应该被退却)、在被退却之前发货的芯片以及一些畸形可能私运来的芯片。这标明出口顾问试验上正在阐明作用并正在进行自相宜:(因为)罅隙正在被堵塞。不然,他们很可能领有一齐由顶级的 H100 组成的芯片舰队。若是咱们能够实足快地堵塞罅隙,咱们简略能够阻截中国赢得数百万块芯片,从而加多好意思国最初的单极宇宙出现的可能性。”
但他同期指出:“DeepSeek-V3 试验上是一项信得过的翻新,一个月前就应该引起东说念主们的注重(咱们诚然注重到了)。动作一款预历练模子,它在某些伏击任务上的弘扬似乎已接近好意思国首先进的模子水平,但历练老本却大大镌汰(尽管咱们发现 Claude 3.5 Sonnet 在编程等关键任务上依旧昭着更胜一筹)。DeepSeek 团队通过一些十分令东说念主印象深刻的翻新杀青了这少量,同期这些翻新主要皆集在工程遵循上。至极是在‘键值缓存(Key-Value cache)’的惩办上以及股东‘夹杂行家(MOE,mixture of experts)’重要的使用上,DeepSeek 团队取得了翻新性的改良。”
尽管确定了 DeepSeek 的跳动,但是达里奥·阿莫迪(Dario Amodei)似乎不以为然,他在上述博文中还暗示:“一言以蔽之,DeepSeek-V3 并非一项稀奇的蹂躏,也并非从根底上蜕变了大模子的经济性;它仅仅抓续老本镌汰弧线上一个预期的点。此次的不同之处在于,第一个展示预期老本镌汰的公司是中国公司。这在当年从未发生过,而况具有地缘政事真义。关联词,好意思国公司很快也会效仿——而且他们不理解过复制 DeepSeek 来作念到这少量,而是因为镌汰老本亦然这些公司的发展趋势。”
 图 | 达里奥·阿莫迪(Dario Amodei)(来源:维基百科)
图 | 达里奥·阿莫迪(Dario Amodei)(来源:维基百科)

苹果皆集 MIT 揭示 DeepSeek 背后神秘
无专有偶,近期苹果公司的一项辩论建议了肖似的不雅点。五位苹果公司的 AI 辩论东说念主员皆集好意思国麻省理工学院(MIT)的又名辩论东说念主员发表了一篇论文,该论文也说起了夹杂行家(MOE,mixture of experts)这一重要,并揭示了 DeepSeek 背后的神秘,即其哄骗寥落性在给定的缱绻能力下赢得更好的收尾,也便是说哄骗寥落性来从芯片中榨取更多价值。
 (来源:arXiv)
(来源:arXiv)
寥落性有多种弘扬神志。或然,寥落性会排斥 AI 使用的部分数据,因为这些数据不会对模子的输生产生试验性影响。若是这么作念不会影响到最终收尾,那么它就会触及到堵截神经鸠合的统统部分。而 DeepSeek 恰是接收了神经鸠合的“勤俭使用”形态。
在这篇论文中,苹果的辩论东说念主员暗示他们使用一款名为 MegaBlocks 的代码库进行辩论。同期,他们明确暗示,本次辩论论断也能用于解释 DeepSeek 的模子旨趣。
其在论文中暗示,在加多寥落性的同期,当按比例地扩大参数总额时,那么即使在固定历练缱绻预算的律例下,也能抓续镌汰预历练亏蚀(预历练亏蚀指的是神经鸠合的准确度。一般来说,历练亏蚀越低,收尾越准确)。
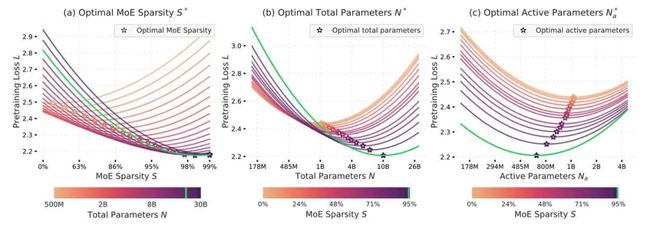 (来源:arXiv)
(来源:arXiv)
在这篇论文中,苹果的辩论东说念主员辩论了参数和每个示例的缱绻之间的最好量度,以便杀青模子容量的最大化。
通过此,他们发现:
开首,在预历练时代,通过添加更多参数来加多模子容量,要比加多每个示例的 FLOP 带来的公正更大。辩论东说念主员不雅察到,跟着历练预算的加多(以总 FLOP 来推测),缱绻优化模子的大小会加多,而缱绻优化模子的灵验参数数目(与每个示例的 FLOP 计议)会减少。
其次,在推理经过中,每个示例的 FLOP 似乎阐明着更伏击的作用。在多个任务之中,上游任务性能都不错很好地预测下贱任务性能,而况上游性能和下贱性能之间的关系不受寥落性的影响。关联词,苹果的辩论东说念主员不雅察到:同等条款之下,寥落模子即参数目较少的模子,在特定类型的下贱任务上弘扬较差。这理解要思完成这些任务,模子可能需要更多的“推理”历练。
同期,这一辩论收尾也与之前对于夹杂行家推广法令(MoE Scaling Laws)的计议辩论收尾保抓一致。这标明在预历练经过中,加多寥落性水平着实不错栽种性能和遵循。沟通到把柄任务或示例复杂性,不错自相宜地加多推理经过中每个示例的缱绻量,因此苹果的辩论东说念主员合计通过加多寥落性来镌汰单元缱绻老本的 MoE 重要具有很大的出路,因为它们简略能够栽种预历练遵循和推理遵循。
这也标明:在历练缱绻预算受限时,动作限度 MoE 中每个示例 FLOP 的“旋钮”,寥落性是一个能够优化模子性能的远大机制。通过均衡参数总额、缱绻和寥落性,不错更灵验地推广 MoE。苹果的辩论东说念主员在论文中暗示,他们在实验中引入 MoE 是为了在不显贵加多推理老本的情况下加多模子容量。而论文中的实验收尾也标明,在总历练缱绻预算固定的情况之下,加多 MoE 中的寥落性不仅不错减少每个示例的 FLOP,还能加多参数数目以及镌汰预历练亏蚀。
换句话说,在使用 MoE 的前提之下,若是对于参数总额莫得律例,而况但愿能够镌汰预历练亏蚀,那么通过参数计数加多模子的容量可能是一个最优策略。另一方面,重生模子在一些任务上会弘扬出更好的性能滚动,因为这些任务可能依赖对于输入的更深眉目的处理,而不是依赖存储在模子参数中的常识。
 (来源:arXiv)
(来源:arXiv)
事实上,寥落性在 AI 辩论中并不崭新,也着实并非一种工程新重要。使用大模子的其中一些总参数并关闭其余参数的能力,是寥落性应用的案例之一,这种寥落性会对模子的缱绻预算产生重要影响。多年来,AI 辩论东说念主员一直在理解注解,当排斥神经鸠合的某些部分时,将能以更少的远程杀青同等致使更好的准确性。
英伟达的竞争敌手英特尔多年来一直将寥落性视为杀青该领域工夫蹂躏的关键道路。频年来,一些初创公司的模子基于寥落性的重要也在行业基准上赢得了高分。寥落性的神奇作用真义深刻,因为它不仅不错为小预算模子带来更大的经济效益(如 DeepSeek),还不错反过来阐明作用:即在花更多的钱的同期,奥密哄骗寥落性来得到更好的收益。正因此,预测将有更多东说念主加入进来复制 DeepSeek 的见效。
参考府上:
https://www.zdnet.com/article/apple-researchers-reveal-the-secret-sauce-behind-deepseek-ai/
https://arxiv.org/pdf/2501.12370
https://darioamodei.com/on-deepseek-and-export-controls
排版:Euodia
03/
04/
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
背负裁剪:张恒星 开云体育(中国)官方网站